The Hypertext Transfer Protocol (HTTP) is an application layer protocol in the Internet protocol suite model for distributed, collaborative, hypermedia information systems. HTTP is the foundation of data communication for the World Wide Web, where hypertext documents include hyperlinks to other resources that the user can easily access, for example by a mouse click or by tapping the screen in a web browser.
Development of HTTP was initiated by Tim Berners-Lee at CERN in 1989 and summarized in a simple document describing the behavior of a client and a server using the first HTTP protocol version that was named 0.9.
Hypertext Transfer Protocol
That first version of HTTP protocol soon evolved into a more elaborated version that was the first draft toward a far future version 1.0.
HTTP (Hypertext Transfer Protocol) is the set of rules for transferring files — such as text, images, sound, video and other multimedia files — over the web. As soon as a user opens their web browser, they are indirectly using HTTP. Hypertext Transfer Protocol is an application protocol that runs on top of the TCP/IP suite of protocols, which forms the foundation of the internet. The latest version of HTTP is HTTP/2, which was published in May 2015. It is an alternative to its predecessor, HTTP 1.1, but does not it make obsolete.
How HTTP works
Through the Hypertext Transfer Protocol, resources are exchanged between client devices and servers over the internet. Client devices send requests to servers for the resources needed to load a web page; the servers send responses back to the client to fulfill the requests. Requests and responses share sub-documents — such as data on images, text, text layouts, etc. — which are pieced together by a client web browser to display the full web page file.
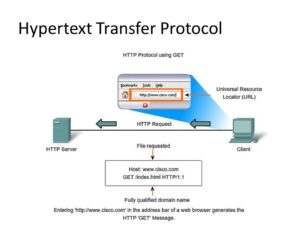
In addition to the web page files it can serve, a web server contains an HTTP daemon, a program that waits for HTTP requests and handles them when they arrive. A web browser is an Hypertext Transfer Protocol client that sends requests to servers. When the browser user enters file requests by either “opening” a web file by typing in a URL or clicking on a hypertext link, the browser builds an HTTP request and sends it to the Internet Protocol address (IP address) indicated by the URL. The HTTP daemon in the destination server receives the request and sends back the requested file or files associated with the request.
To expand on this example, a user wants to visit TechTarget.com. The user types in the web address and the computer sends a “GET” request to a server that hosts that address. That GET request is sent using Hypertext Transfer Protocol and tells the TechTarget server that the user is looking for the HTML (Hypertext Markup Language) code used to structure and give the login page its look and feel. The text of that login page is included in the HTML response, but other parts of the page — particularly its images and videos — are requested by separate HTTP requests and responses. The more requests that are made — for example, to call a page that has numerous images — the longer it will take the server to respond to those requests and for the user’s system to load the page.
When these request/response pairs are being sent, they use TCP/IP to reduce and transport information in small packets of binary sequences of ones and zeros. These packets are physically sent through electric wires, fiber optic cables and wireless networks.
The requests and responses that servers and clients use to share data with each other consist of ASCII code. Requests state what information the client is seeking from the server; responses contain code that the client browser will translate into a web page. Status codes used by Hyperlinks Protocol are supported by our What Is service.